안녕하세요, 오늘의집 플랫폼 개발자 호성, 데이터 엔지니어 큐큐입니다. 2021년 상반기에 구축한 오늘의집 A/B 실험플랫폼의 구축 과정과 그 속에서 해결한 고민에 대해 공유합니다.
A/B 실험 플랫폼은 프로덕트에 새로운 피쳐를 반영할때 데이터 기반으로, 그리고 과학적으로 여러 안들을 비교하고 의사 결정을 돕는 실험 플랫폼입니다. 이 글을 통해서 오늘의집 플랫폼팀과 데이터팀이 어떻게 실험에 기여하고 데이터가 흘러가도록 만들었는지 소개합니다.
A/B 실험 플랫폼이란?
현재와 새로운 버전들(B.C...N)간 실험 성공지표를 비교(A vs B, A vs C… A vs N)하여 어떤 버전이 가장 좋은 성과를 보이는지를 실험을 생성한 PO가 판단할 수 있도록 도움을 주는 플랫폼입니다.
- 좋은 성과? - 하나의 A/B 실험의 가설을 세울 때 측정하고자 하는 한 개의 성공지표(CTR, CVR, Conversion 등)와 여러 개의 보조지표, 그리고 전사관점의 가드레일 지표(실험으로 영향받는 전사지표) 등을 검토하여 측정합니다.
우리의 미션
이 프로젝트를 시작하기 전에도 이미 오늘의집에는 A/B 실험을 위한 서비스가 존재했습니다. 다만 실험의 시작/종료, 그리고 실험군의 비율 조정을 위해서는 서비스의 배포가 필요했습니다. 자동화된 분석 또한 없었습니다. 이런 불편함으로 Product 조직 내에서 A/B 실험이 활성화되지 않았고 대부분의 피쳐들이 배포 전/후 지표를 측정하여 성과를 비교하고 있었습니다.
이러한 불편함을 개선하는 동시에 피쳐의 정확한 성과측정 및 빠른 의사결정을 돕기 위해 A/B 실험 플랫폼을 구축하기로 결정하였습니다.
A/B 실험 플랫폼 시스템
Requirements
- 실험의 시작/중지/수정은 실시간으로 반영되어야 한다.
- 실험에 참여한 실험군의 로그를 실시간으로 확인할 수 있어야 한다.
- 실험으로 인해 서비스 latency에 영향이 있으면 안 된다.
- 세션 기준 실험군 지정이 되면 같은 실험에서 동일 세션의 실험군은 변경되지 않는다.
- Winner가 선정되어 종료된 실험의 실험군은 불변해야 한다.
- 실험지표에서 통계적 유의성을 확인할 수 있어야 한다.
- 실험은 동시에 여러 개가 실행될 수 있다.
System Architecture Overview

A/B 실험 플랫폼 설계에서 중요하게 고려한 부분은 아래와 같습니다.
- 사용자의 Page latency에 영향이 없어야 한다.
- 사용자에게 배정된 실험군은 재 접속시 바뀌지 않아야 한다.
- 실험정보의 변경은 사용자에게 실시간으로 업데이트 되어야 한다.
위 요건들을 기반으로 기술 스택을 선정하고 실험 플랫폼/데이터 파이프라인을 설계하였습니다.
Tech Stack
- Frontend: React
- Backend: Kotlin, Go, Kafka, mongoDB, ElasticCache
- Data: Python, Spark, Scala, ksqlDB, Airflow
데이터팀의 변인통제
실험의 관리자는 실험이 필요한 기획을 제안하며 실험 플랫폼에 해당 기획에 필요한 내용들을 함께 첨부합니다.

해당 내용을 통해 Product Owner(이하 PO), Data Scientist(이하 DS) 등이 실험 계획을 점검하고 해당 실험에 오류가 없는지, 다른 실험을 통해 영향 받을 가능성이 없는지, 신규 피쳐 여부, 통제된 환경에서 실험이 진행되는지 등을 함께 확인합니다. 승인 프로세스가 도입되지 않았지만, 이후에 실험의 승인 시스템도 실험 플랫폼에 추가하여 더 정확한 실험이 생성되길 기대합니다.
데이터 관점에서의 실험 플랫폼
실험 플랫폼 개발에 있어서 데이터팀의 과제는 다음과 같습니다.
- 유니크한 키를 기준으로 실험군을 일관되게 내려줄 것 (Randomizer)
- 클라이언트가 보내는 로그를 적재할 것 (AB-log)
- 실험의 결과를 주기적으로 분석하여 결과를 A/B 실험 플랫폼으로 보낼 것 (데이터 집계, 통계 검정)
Randomizer
데이터팀이 Randomizer에 설정한 스펙은 아래와 같았습니다.
- 실험의 생성, 업데이트, 시작, 종료를 가능하게 할 것
- 시작된 실험에 대해서 유니크한 키를 기준으로 실험그룹(Control Group, Treatment Group)을 내려줄 것
- 실험군 배정 비율을 변경할때, 변경되는 실험군은 최소한으로 유지할 것
1번 항목의 실험의 생성, 업데이트, 시작, 종료를 구현하는 것은 생각보다 간단했습니다. 캐시 레이어로 사용하고 있던 Redis를 데이터 저장소로 사용하여 실험들의 스펙과 현재 어떤 실험들이 진행 중인지 저장했습니다.

Randomizer가 핵심적으로 가져야 할 기능은 2번 항목이었습니다. 어떻게 실험의 오류 없이 빠른 속도로 분기를 해줄 수 있을까 고민을 했습니다. 반복적으로 들어오는 Randomize 요청에 Deterministic하게 응답해야했고 관리자가 설정한 비율대로 올바르게 배정해줄 수 있는 알고리즘이 무엇이 있을까 고민했습니다. 결국 Randomizer를 구현함에 있어서는 Facebook의 Planout이라는 라이브러리를 사용했습니다.
Planout 내부적으로 구현된 방식은 결국 간단한 hash function입니다. 실험마다 고유한 salt를 정해두고, 이 salt와 함께 유니크 키를 0~1의 값으로 hashing하고 유저가 선택한 비율로 이 0~1의 hash value를 잘라내어 분배합니다. 간단한 알고리즘이지만 Planout은 이를 확장 가능한 방식으로 인터페이스를 제공한다는 점에서 편리했습니다. 개발자는 planout의 Python Class만 상속하여 개발하면 Randomizer의 기능을 커스터마이즈 해서 사용할 수 있습니다. 논문에서 해당 내용을 담고 있는 PlanoutOp를 살펴보면 아래와 같이 이루어져 있습니다.
class PlanOutOpRandom(PlanOutOpSimple):
LONG_SCALE = float(0xFFFFFFFFFFFFFFF)
def getUnit(self, appended_unit=None):
unit = self.getArgMixed('unit')
if type(unit) is not list:
unit = [unit]
if appended_unit is not None:
unit += [appended_unit]
return unit
def getHash(self, appended_unit=None):
if 'full_salt' in self.args:
full_salt = self.getArgString('full_salt') + '.' # do typechecking
else:
full_salt = '%s.%s%s' % (
self.mapper.experiment_salt,
self.getArgString('salt'),
self.mapper.salt_sep)
unit_str = '.'.join(map(str, self.getUnit(appended_unit)))
hash_str = '%s%s' % (full_salt, unit_str)
if not isinstance(hash_str, six.binary_type):
hash_str = hash_str.encode("ascii")
return int(hashlib.sha1(hash_str).hexdigest()[:15], 16)
def getUniform(self, min_val=0.0, max_val=1.0, appended_unit=None):
zero_to_one = self.getHash(appended_unit) / PlanOutOpRandom.LONG_SCALE
return min_val + (max_val - min_val) * zero_to_one
실험의 비율이 바뀌어도 hash는 달라지지 않고(달라지지 않게 salt를 설계해야 합니다) getUniform 결과 또한 동일하므로 3번의 요구사항도 충족할 수 있었습니다. 이처럼 bucketing logic이 planout 라이브러리에 의존적이지만 향후 SDK 구현시에는 성능 향상을 위해 murmurHash, CityHash와 같은 Hash 함수 사용을 고려하고 있습니다.
현재 인프라는 Nginx+uwsgi+flask로 Randomizer를 구성하여 EKS 위에서 운영하고 있습니다. 실험이 늘어남에 따라 점점 더 많은 트래픽을 안정적으로 받아낼 수 있도록 고민한 결과였습니다. Stress 테스트 후에 최종적으로 위 인프라를 채택하여 반영했습니다. Stress 테스트에는 AB(Apache Benchmark)와 Locust를 활용했습니다. 당시의 스크립트를 살펴보면, 이런 식으로 재밌게 테스트를 했었네요.
from locust import HttpUser
# 유저는 정해진 행동을 순서대로 한다. 그러는 와중에 틈틈이 ABExperiment 에 참여한다고 가정.
# 실험에 관해서 유저가 할 수 있는 행동
## 1. 현재 자신이 참여가능한 실험 리스트, 정보 받아오기
## 2. 해당 페이지에 들어가는 순간 실험군 분기
## 3. 자신이 행동과 실험군, 실험 정보를 로깅
# 유저가 할 수 있는 로그는 production log 를 replay하는 방식으로 재현한다
class ExperimentUser(HttpUser):
def get_current_experiments(self):
pass
def get_ab(self, experiment_id):
pass
def log_action(self, data):
pass
def log_ab(self, data):
pass
@task(1)
def action(self):
pass
def on_start(self):
pass
def log_mocking():
"""
load production log, replay, create ExperimentUser with mocked log
전일자의 로그를 불러와서 ExperimentUser를 생성하고,
더 높은 트래픽으로 stage 환경에 실제 실험이 돌아가는 것처럼 테스트했습니다.
"""
pass
# 구현부분들은 지워두었습니다.
콜의 순서가 정해져있다보니 Apache Benchmark보다는 Locust가 의미있는 테스트를 하기에 좋았습니다. Apache Benchmark는 필요한 로깅까지 해주지는 않으니까요. 로그를 replay하면서 실제로 stage A/B실험의 자동화 분석까지 테스트할 수 있었습니다. 전체적인 테스트 흐름은 아래 이미지와 같습니다. 메뚜기 같이 생긴 친구가 Locust에 해당합니다.
Randomizer를 통해 올바른 실험군을 배정받은 클라이언트는 분기된 피쳐를 유저에게 노출시키고 노출 로그를 ab test log로 보내도록 테스트를 실행했습니다.

테스트는 peak tps 대비 10x request로 설정하여 진행하였고 결과는 TP95 30ms로 3번 항목의 목표에 부합되어 위 설계로 결정하였습니다.
AB Test Log
기존의 오늘의집 로그들은 AWS managed service인 Kinesis를 이용했었습니다. 그러나 로그 양이 점점 많아짐에 따라 비용 문제와 운영 난이도가 오히려 증가하는 이슈를 겪었습니다. 결국 플랫폼팀의 도움을 받아 Kafka와 함께 Kafka Connect 를 사용하여 로그 파이프라인을 다시 구성하였습니다.

카프카 커넥트(Kafka Connect)란?
카프카 커넥트는 다양한 데이터 소스와 목적지에 맞게 데이터를 발행하거나 구독할 수 있게 해주는 confluent platform의 구성요소인데요, Consumer 와 Producer의 기능을 설정만으로 구성할 수 있는 점에서 매력적이었습니다.
S3, Cloud Storage, JDBC, etc.. 등과 같은 다양한 플러그인이 있어 필요한 플러그인을 적절하게 설치해서 연동할 수 있습니다.
confluent-hub install confluentinc/kafka-connect-s3:5.5.3

두 종류의 Kafka connectors
- Source connector
- Sink connector
Source connector는 시스템으로부터 데이터를 수집하는 커넥터로서 소스 시스템은 전체 데이터베이스, 스트림 테이블 또는 메시지 브로커가 될 수 있습니다. 또한 Source connector는 kafka topic으로 metric을 수집하여 짧은 대기 시간만으로 stream processing에 사용할 데이터를 만들 수 있습니다.
Sink Connector는 외부 시스템으로부터 Elasticsearch의 인덱스, hadoop과 같은 분산 처리 시스템 또는 데이터베이스 등으로 데이터를 저장하는데 사용됩니다.

원하는 source와 destination에 맞게 plugin을 설치하셔서 사용하면 됩니다. Source connector와 Sink connector을 적재적소에 배치함으로써 Kafka가 실시간 데이터의 Hub처럼 동작할 수 있게 해줍니다.
클라이언트가 호출할 수 있는 로그 서버를 앞에 두고, 로그 서버가 클라이언트로부터 로그를 받아 Kafka에 보내면 Kafka Connect를 통해서 S3로 적재가 됩니다. S3에 적재가 된 로그 데이터는 Hive External Table Format을 따르도록 아래와 같이 Kafka S3 Sink connector에 설정을 해두었습니다.
"partitioner.class"='io.confluent.connect.storage.partitioner.TimeBasedPartitioner',
"partition.duration.ms"=3600000,
"path.format"='\\''date\\''=YYYY-MM-dd'''
A/B 로그를 실시간 스트림으로 실험 플랫폼에서 확인하고자 하는 니즈도 있었습니다. 관리자가 실험군 비율이 올바른지, 로그 형식은 제대로 들어오는지, 각 실험군의 테스트를 위한 실험군의 오버라이드가 정상적으로 되었는지 모니터링하기 위해서는 실시간 로그스트림이 필요했습니다. 카프카에 들어오는 로그를 S3에 적재함과 동시에 스트리밍할 수 없을까 고민하던 중에 Confluent에서 개발한 Kafka Stream을 고려하게 되었습니다.
카프카 스트림(Kafka Stream)
스트림 데이터를 위해 선택할 수 있는 선택지가 많았습니다. 스트림데이터에 크게 해야할 프로세싱이 없었기에 Kafka Stream을 선택했습니다. 토픽을 구독하고, 이를 stateless, stateful 또는 window 단위로 처리할 수 있는 스트림 프로세싱 jvm library입니다. 구독하는 토픽으로부터 데이터를 가져오고, 이를 처리해서 다시 카프카로 밀어넣는 처리를 가능하게 합니다. 토픽을 처리해서 또 다른 토픽을 만드는 경우에 유용한 것 같습니다.
Kafka Stream은 크게 Stream API와 Table API로 이루어져있습니다. Stream은 스트리밍 되어오는 데이터의 변화, Table은 해당 변화를 통해서 변화된 데이터의 상태를 담고 있습니다.
커넥트와 스트림을 어떻게 생성하고 관리했나
카프카 커넥트와 스트림을 함께 사용하려면 개발/인프라 복잡도가 올라가는데, 한정된 리소스에서 이를 실행하기에는 어려움이 많은 상황이었습니다.
이런 복잡도를 해결하며 리소스를 절감할 수 있는 방법은 없을지 논의하는 과정에서 ksqlDB를 도입하게 되면 우리의 고민을 해결할 수 있는지 검토하게 되었습니다. ksqlDB는 KSQL+Connect management+Stream management의 기능들을 sql만으로 관리할 수 있게끔 복잡도를 낮춘 프레임워크였습니다. https://ksqldb.io/overview.html
ksqlDB에서는 ease of use를 강조하고 있습니다.

아래와 같이 기존의 scala로 Kafka Stream을 만들고, Producer Consumer를 만들고, DB에 적재하고, 이를 클라이언트가 가져가는 처리를 ksqlDB는 KSQL로 모두 생성하고, 관리할 수 있게 되는 것이죠. (너무 멋지지 않나요~:>)

이런 DDL만으로 관리가 가능해집니다.
Create stream experiment_log (experiment_id bigint, experiment_version bigint, uuid varchar, variation_group varchar, platform varchar, platform_version varchar, timestamp bigint) with (
KAFKA_TOPIC = 'ab-test-exposure',
VALUE_FORMAT = 'JSON'
);
ksqlDB를 통해서 REST API로 Kafka에 KSQL쿼리를 던지고, 실시간 데이터를 응답 받으며 Kafka Connector의 생성과 관리도 더욱 간편해졌습니다. 아래는 KSQL에 REST로 쿼리하여 데이터를 응답 받는 예시입니다.
curl --http2 -X "POST" "<http://localhost/query-stream>" -d $'{
"sql": "select * from `experiment_log` and experiment_id=51 emit changes;",
"streamsProperties": {}
}'
실시간으로 토픽에 들어오는 이벤트를 필터링하고 집계한다는 점에서 적용해볼 만한 스택이라고 생각했습니다. 매번 비슷한 태스크가 생길 때마다 컨슈머를 만들어 구현하지 않고, Kafka Connect와 KSQL을 적재적소에 사용하면 꽤나 편하게 이벤트를 다룰 수 있음을 확인했습니다.

분석 파이프라인
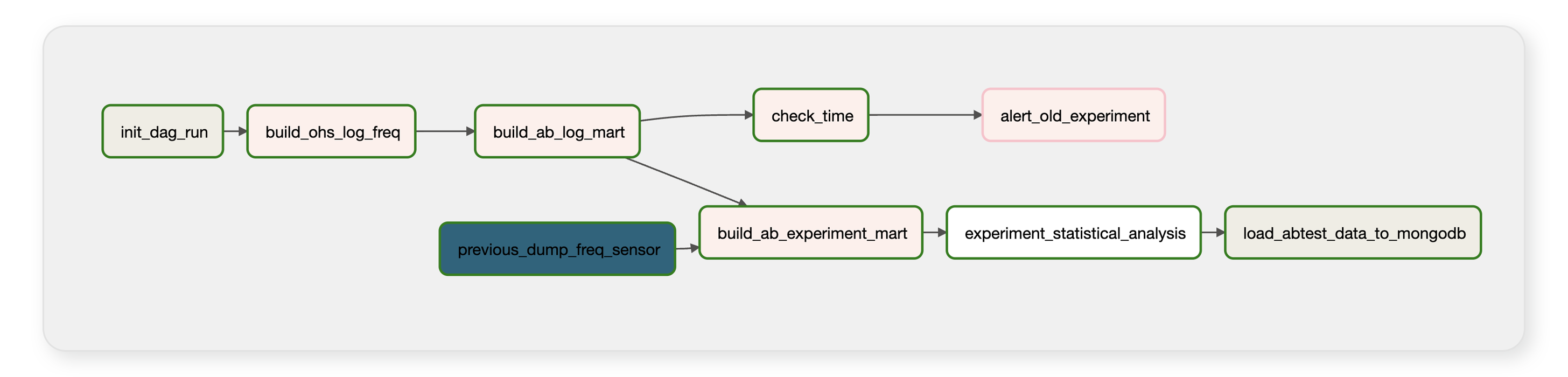
위의 로그 파이프라인을 통해 적재된 AB Log는 사용자 행동로그(Ohs Log)와 함께 한 시간 단위로 합쳐지고, 합쳐진 로그는 실험의 마지막 revision time부터 누적으로 분석이 됩니다.
분석은 Spark on EMR, Airflow에서 이루어집니다. 한 시간 단위의 실험 데이터마트를 만들고, 이를 가져다가 지표분석, 통계검정, 분석이 완료된 데이터를 다시 실험 플랫폼으로 적재하기를 반복합니다.
실험관리자는 실험 시작전에 실험 분석에 필요한 지표들을 고르게 됩니다. 수많은 Metric들이 존재하는데, 이는 모두 각 팀의 분석가들이 실험의 계획단계에서부터 참여하여 설계한 지표들입니다. 각 분석가들은 정해진 DSL 문법에 맞게 지표를 작성하게 됩니다. 그럼 해당 실험의 지표를 받아 Airflow*가 DSL을 파싱하고, 자동화된 분석을 수행합니다. 지금까지 총 100여 개의 지표가 생성되어 실험에 사용되고 있습니다. (*오늘의집 Airflow가 궁금하다면? 클릭)
지표들은 세 가지 종류의 메트릭으로 구성되어있습니다.
- Standard Metric: 팀의 KPI와 전체 서비스의 성과를 나타내는 지표
- Custom Metric: 해당 실험, 해당 페이지에서 사용되는 특수한 지표
- Guardrail Metric: 실험으로 인해 서비스 주요지표(GMV, Retention, Conversion…)에 영향이 가는지 확인하기 위한 지표
자동화 분석을 통해 각 지표는 통계검정을 위해 필요한 정보들을 함께 내보냅니다. 예를 들어, CTR(Click Through Rate)이 지표인 경우에 노출 유저 수와 클릭 유저 수를 함께 집계합니다. 이렇게 통계 검정을 위해 모든 집계가 완료되면 DS가 작성한 통계 검정 모델을 통해서 p-value, confidence interval 등을 계산하고 sample mismatch ratio test, power analysis 등을 통해 결과를 검증하고 모니터링합니다.
그렇게 모든 집계와 통계 검정이 완료되면 해당 결과는 Hive table 형태로, 그리고 실험 플랫폼에 보내지게 됩니다. 보내진 결과는 실험관리자들이 볼 수 있도록 아래와 같이 노출됩니다. 해당 지표들을 통해서 실험관리자는 실험의 초기단계부터 한 시간 단위로 분기가 제대로 되고 있는지, 실험 데이터마트를 통해 분기된 유저들이 어떻게 다르게 행동하는지, 이에 따라 지표가 어떻게 변하는지를 확인할 수 있습니다.


실험플랫폼이 가야할 길
위에서 설명한 실험 플랫폼 중 데이터 인프라를 요약하면 아래와 같습니다.

실험 플랫폼 런칭 후 약 6개월 간 80여 개의 실험이 생성되고 55개의 실험이 종료되었습니다. 더욱 발전된 형태의 실험을 하기 위해 데이터팀이 개선해야할 부분들이 아래와 같이 아직도 많이 있습니다.
- 실험 승인 프로세스
- 유저의 속성(성별, 나이대)을 포함해서 randomize
- AA 테스트 등의 실험 validation
- 분석 프로세스 단순화
- 실험과 실험 사이의 관계 생성 (부모 실험, 자식 실험)
- etc.
2개월 간 PO, 플랫폼팀과의 협업을 통해 실험 플랫폼을 개발하며 많은 것을 고민할 수 있었습니다. 인프라도, 데이터도 무엇 하나 정확하게 동작하지 않으면 어려웠던 개발이었습니다. 이제 겨우 한 단계를 밟았으니 이후에는 DS와 긴밀한 협업을 통해 더욱 과학적인 실험 플랫폼으로 개선되기를 기대하고 있습니다.
협업을 하면서
실험에 관한 배경지식도 달랐고, 플랫폼을 바닥부터 구현해 본 경험도 모두 달랐습니다. 결국 회의와 스터디, 스크럼을 통해서 조금씩 해결해 나갔습니다. 다행히 실험 플랫폼을 경험해보신 좋은 PO, 플랫폼 개발자 분들이 함께해 주셔서 완수할 수 있었습니다.
사실 같은 프로젝트를 진행하더라도 데이터팀이 고민해야할 것들과 플랫폼팀이 고민해야할 것들은 주제가 많이 다를 때가 있습니다. 이번 프로젝트에서는 TF에서의 협업과 각자 팀에서의 협업이 유기적으로 연결되어 있었기에 함께 문제를 해결하며 잘 마칠 수 있었습니다.

