
버킷플레이스 데이터 플랫폼에서는 오늘의집 서비스에서 발생한 다양한 데이터를 수집하고 가공하여 오늘의집 구성원과 데이터가 필요한 사용자, 서비스에 제공하는 역할을 하고 있습니다. 버킷플레이스에서는 데이터를 기반으로 의사결정을 진행하기 때문에 빠르고 정확하게 데이터를 제공하는것이 매우 중요합니다.
2020년 오늘의집 서비스가 빠르게 성장하면서 데이터 플랫폼의 크기와 복잡도가 점점 커졌습니다. 또한 데이터를 바라보는 사용자와 연관된 서비스가 증가하였습니다. 이에따라 데이터 플랫폼의 Job Task 하나하나가 더 중요해졌고, 하나의 Task 실패는 여럿의 생산성을 크게 해치는 결과를 낳았습니다. 이런 문제를 해결하기 위해 2020년 후반기부터 다양한 데이터 플랫폼 개선 작업을 진행하고 있는데, 그 중 하나가 데이터 워크플로우 개선, Airflow 도입 이였습니다.
기존 버킷플레이스 데이터팀은 젠킨스를 이용하여 데이터 파이프라인을 만들고 운영하고 있었습니다. 젠킨스를 사용하는것은 크게 문제는 없었지만,



등을 이유로 Airflow로의 전환을 고민하기 시작했습니다.
Airflow란?
Airflow는 Python 코드로 워크플로우(workflow)를 작성하고, 스케쥴링, 모니터링 하는 플랫폼입니다. Airflow를 통해서 데이터엔지니어링의 ETL 작업을 자동화하고, DAG(Directed Acyclic Graph) 형태의 워크플로우 작성이 가능합니다. 이를 통해 더 정교한 dependency를 가진 파이프라인을 설정할 수 있습니다. 또한 AWS, GCP 모두 Airflow managed service를 제공할 정도로 전세계 데이터팀들에게 널리 사용되고 있으며 그만큼 넓은 커뮤니티를 형성하고 있습니다.
Airflow 동작 원리
Airflow는 여러가지 구성요소를 가지고 있습니다.

- Scheduler : 모든 DAG와 Task에 대하여 모니터링 및 관리하고, 실행해야할 Task를 스케줄링 해줍니다.
- Web server : Airflow의 웹 UI 서버 입니다.
- DAG : Directed Acyclic Graph로 개발자가 Python으로 작성한 워크플로우 입니다. Task들의 dependency를 정의합니다.
- Database : Airflow에 존재하는 DAG와 Task들의 메타데이터를 저장하는 데이터베이스입니다.
- Worker : 실제 Task를 실행하는 주체입니다. Executor 종류에 따라 동작 방식이 다양합니다.
Airflow는 개발자가 작성한 Python DAG를 읽고, 거기에 맞춰 Scheduler가 Task를 스케줄링하면, Worker가 Task를 가져가 실행합니다. Task의 실행상태는 Database에 저장되고, 사용자는 UI를 통해서 각 Task의 실행 상태, 성공 여부 등을 확인할 수 있습니다.
Airflow DAG(Directed Acyclic Graph)
Airflow의 DAG는 실행하고 싶은 Task들의 관계와 dependency를 표현하고 있는 Task들의 모음입니다. 어떤 순서와 어떤 dependency로 실행할지, 어떤 스케줄로 실행할지 등의 정보를 가지고 있습니다. 따라서 DAG를 정확하게 설정해야, Task를 원하는 대로 스케쥴링할 수 있습니다.
Airflow Operator
각 Airflow DAG는 여러 Task로 이루어져있습니다. operator나 sensor가 하나의 Task로 만들어집니다. Airflow는 기본적인 Task를 위해 다양한 operator를 제공합니다.
- BashOperator : bash command를 실행
- PythonOperator : Python 함수를 실행
- EmailOperator : Email을 발송
- MySqlOperator : sql 쿼리를 수행
- Sensor : 시간, 파일, db row, 등등을 기다리는 센서
Airflow에서 기본으로 제공하는 operator 외에도 커뮤니티에서 만든 수많은 operator들이 Data Engineer의 작업을 편하게 만들어 주고 있습니다.
Airflow Executor 고민
위에서 Worker의 동작이 Airflow Executor의 종류에 따라 달라진다고 설명드렸는데요. Executor는 Task를 실행하는 주체로, 다양한 종류가 있고 각각 다른 특징을 가지고 있습니다. 버킷플레이스 데이터 팀에서는 Production에서 많이 사용되고 있는 Celery Executor와 Kubernetes Executor를 고려해 보았습니다.
먼저, Celery Executor는 Task를 메시지 브로커에 전달하고, Celery Worker가 Task를 가져가서 실행하는 방식입니다. Worker 수를 스케일아웃 할 수 있다는 장점이 있지만, 메시지 브로커를 따로 관리해야하고 워커 프로세스에 대한 모니터링도 필요하다는 단점이 있습니다.
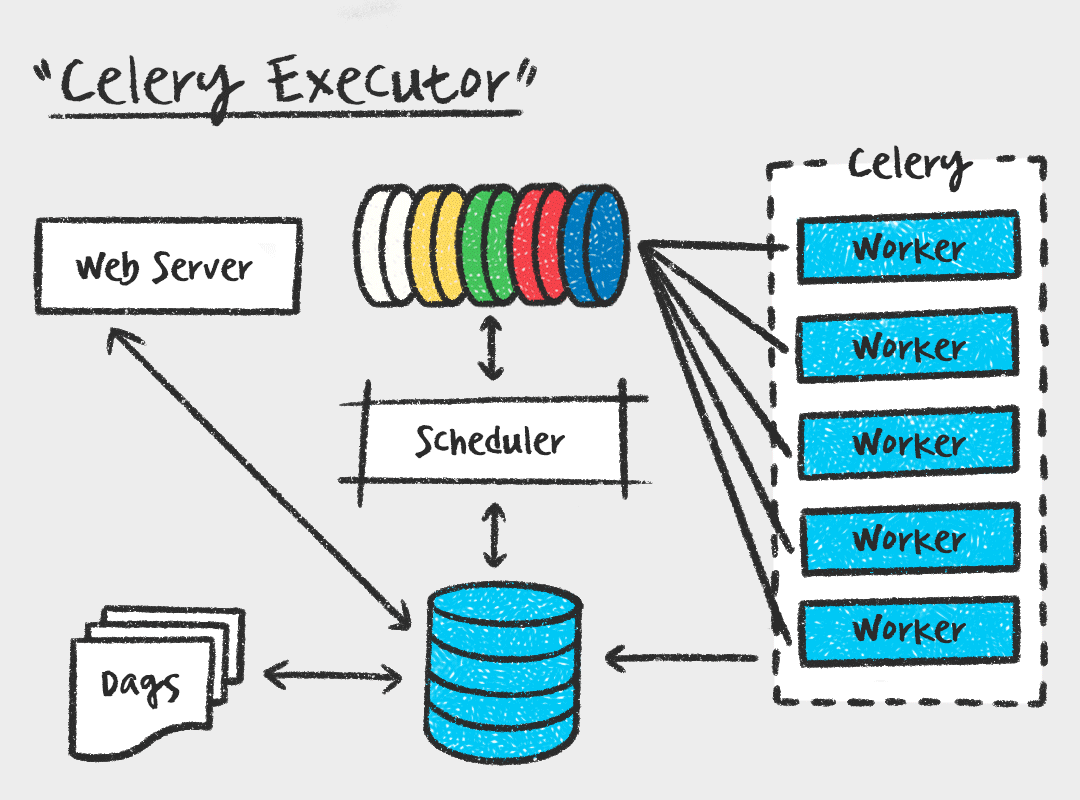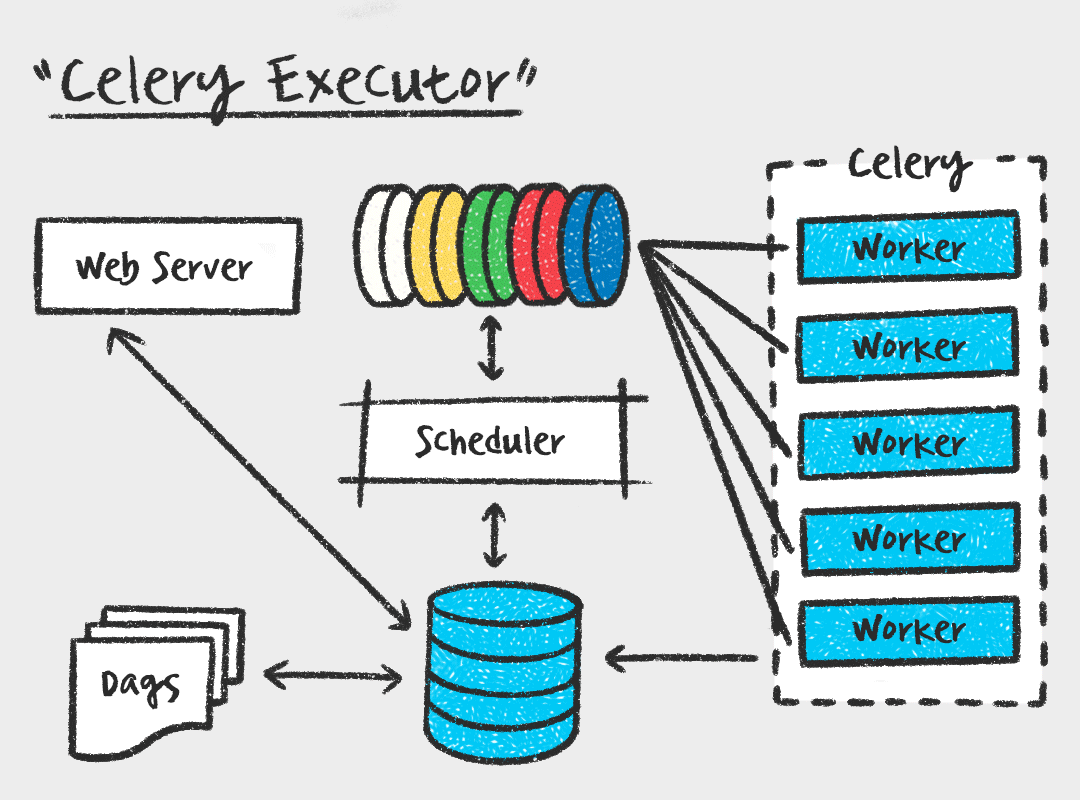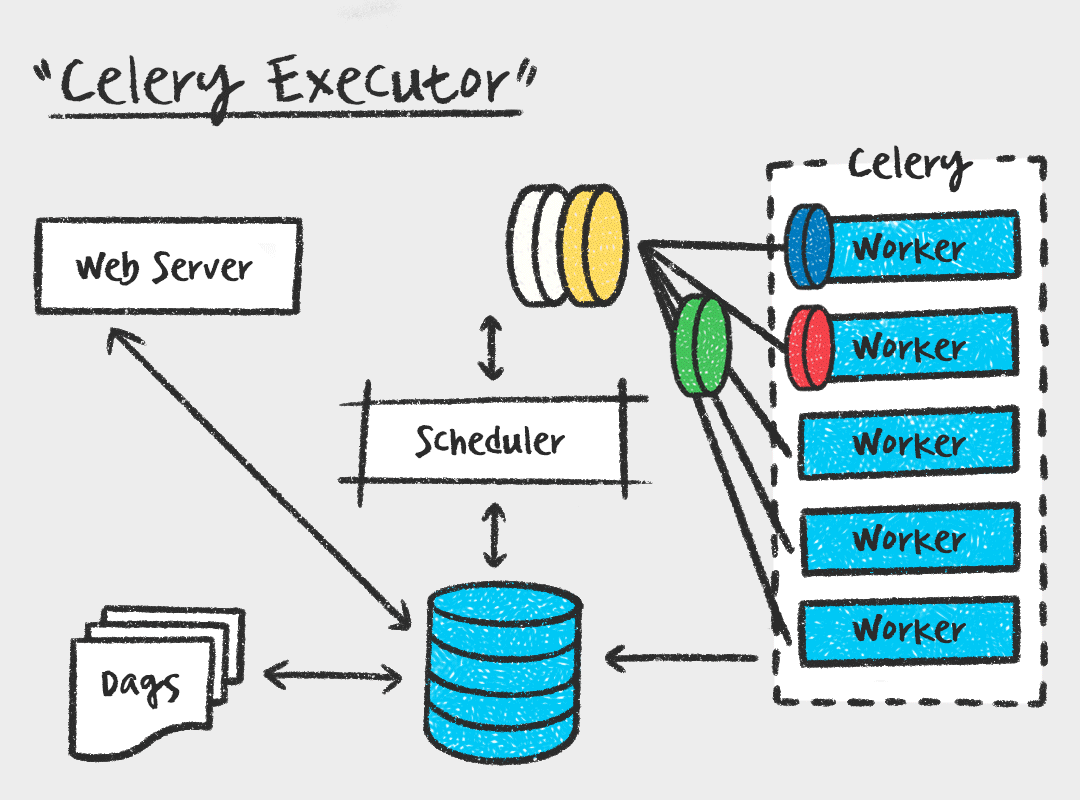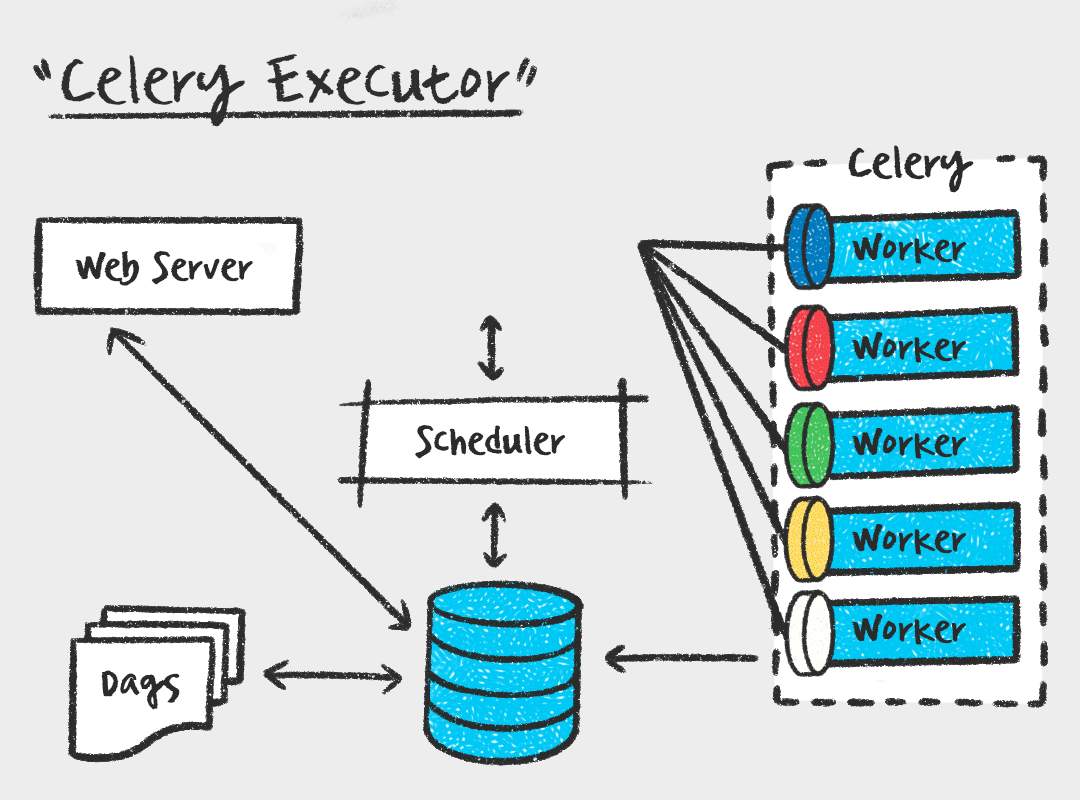
그에 비해 Kubernetes Executor는 Task를 스케줄러가 실행가능 상태로 변경하면 메시지 브로커에 전달하는게 아니라 Kubernetes API를 사용하여 Airflow 워커를 pod 형태로 실행합니다. 매 Task마다 pod가 생성되므로 가볍고, Worker에 대한 유지 보수가 필요없다는 장점이 있습니다. 또한 Kubernetes를 활용하여 지속적으로 자원을 점유하지 않기 때문에 효율적으로 자원을 사용할 수 있습니다. 하지만 짧은 Task에도 pod을 생성하는 overhead가 있으며, celery executor에 비해 자료가 적고 구성이 복잡하다는 단점이 있습니다.

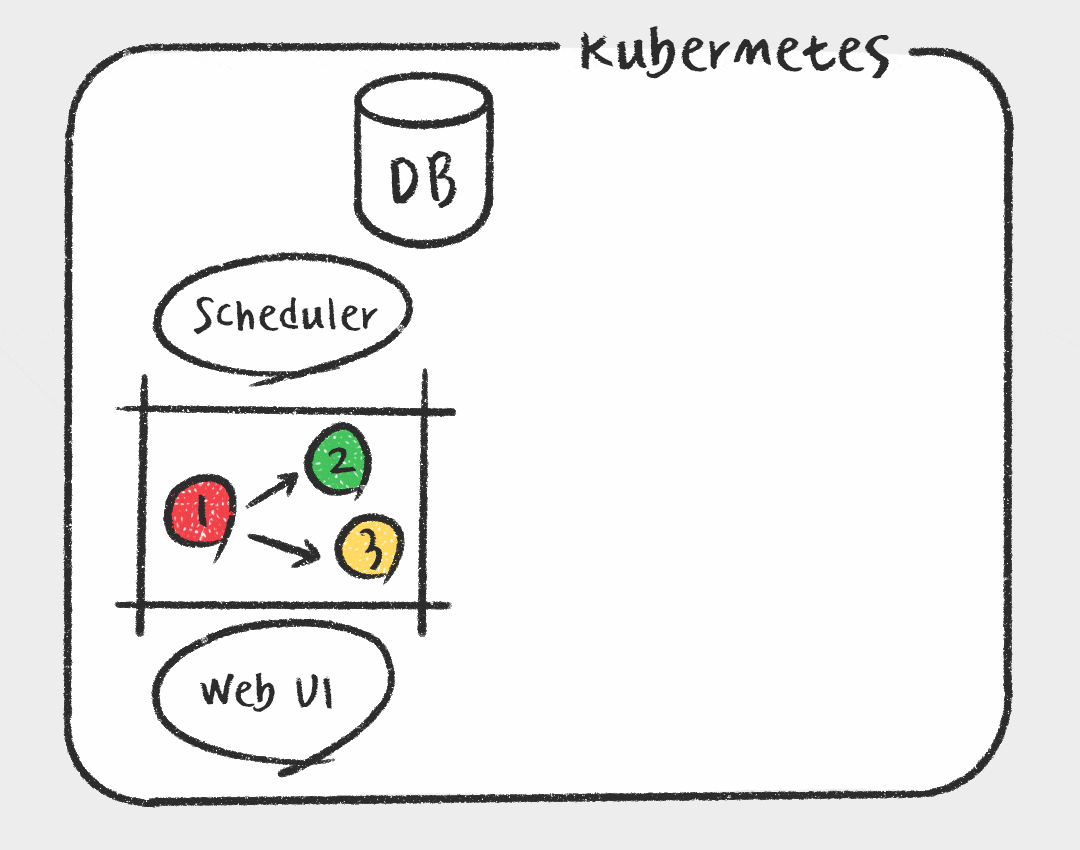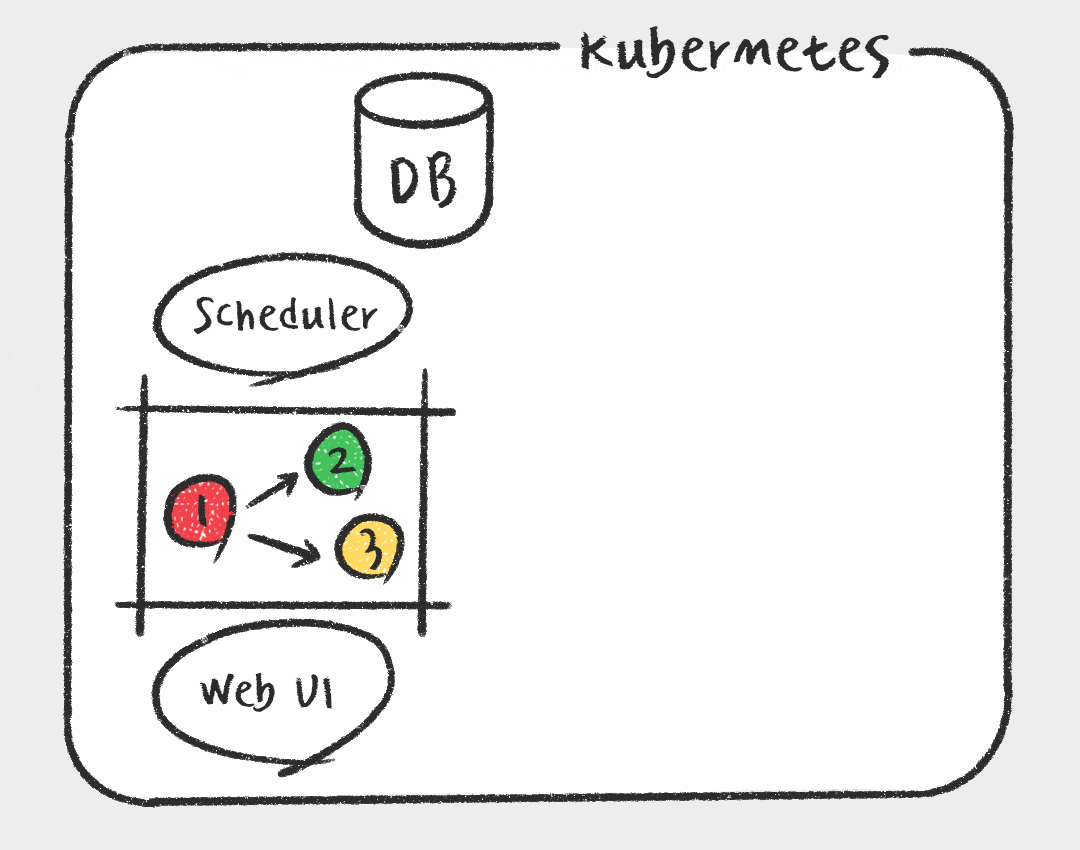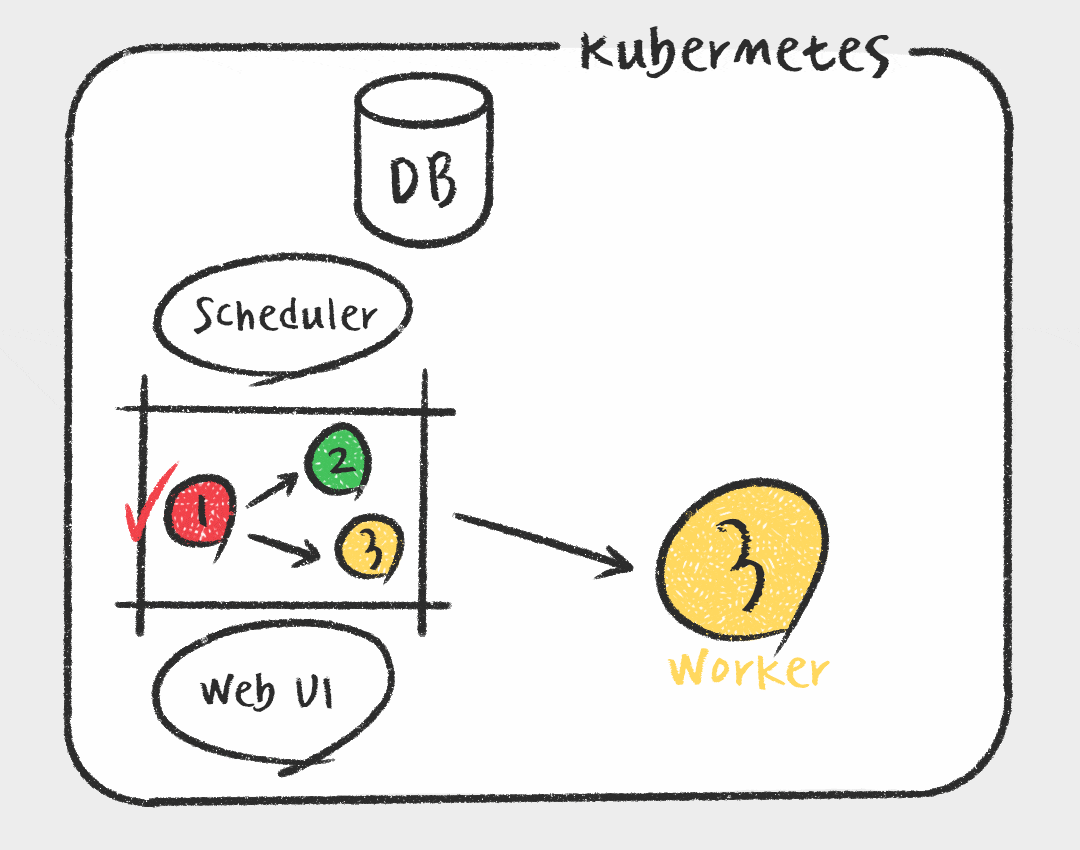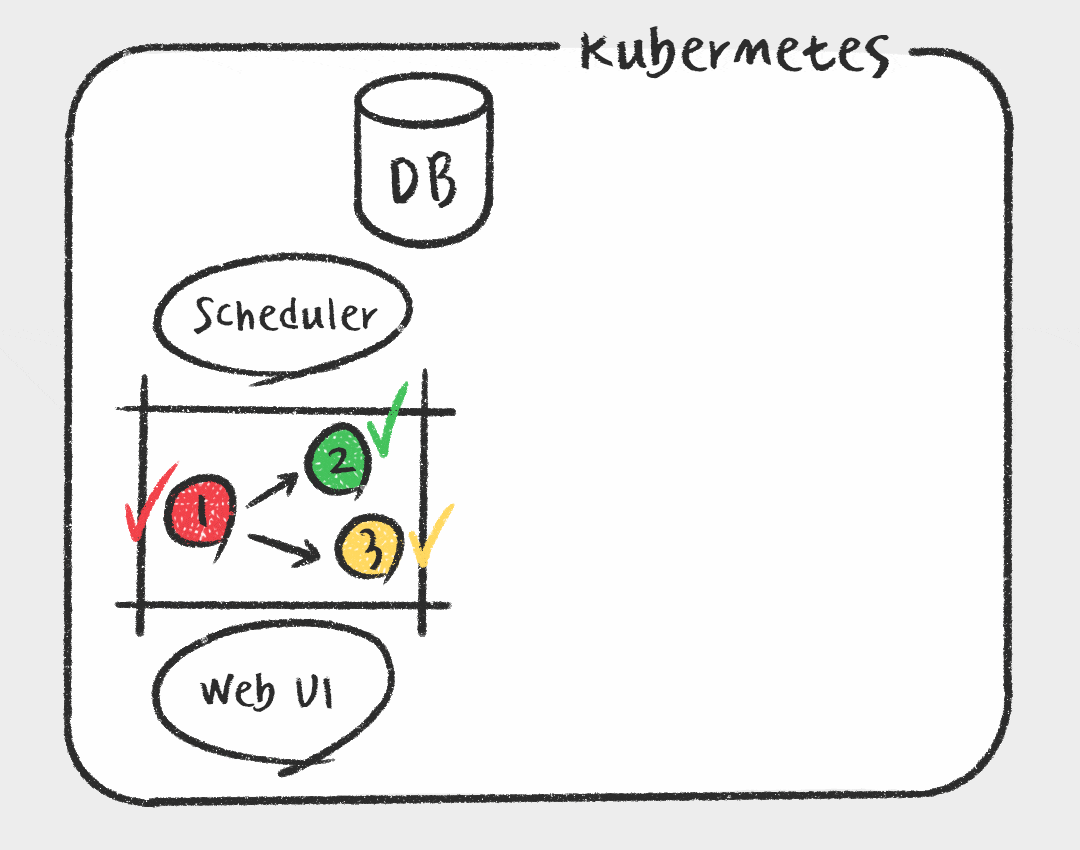
데이터 플랫폼 개선 작업을 할때 가장 중요하게 고려한 점이 안정성과 확장성이기 때문에 Kubernetes Executor를 사용하기로 결정하였습니다. 또한 필요에 따라 Kubernetes API를 활용하여 추후에 Data Scientist를 위한 GPU 인스턴스를 사용하거나, Kubernetes Pod Operator를 사용하여 Python 말고도 R이나 SAS 로 된 Task를 컨테이너 환경에서 지원이 가능할 것으로 예상했습니다. 이러한 관점에서 Kubernetes 환경의 장점을 최대한 살릴수 있는 Kubernetes Executor를 선택하였습니다.
Helm Chart
버킷플레이스에서는 https://github.com/airflow-helm/charts Helm 차트를 기반으로 사용하고 있습니다. Airflow 공식 차트(https://github.com/apache/airflow/tree/master/chart) 가 존재하지만 2021년 3월 기준 아직 정식 릴리즈가 아니여서 사용하지 않았습니다. https://github.com/airflow-helm/charts 는 많은 사람들이 프로덕션 환경에서 사용하고 있고, 블로그와 도큐멘트가 잘 되어있어서 배포에 어려움이 없었습니다.
Kubernetes Executor 설정
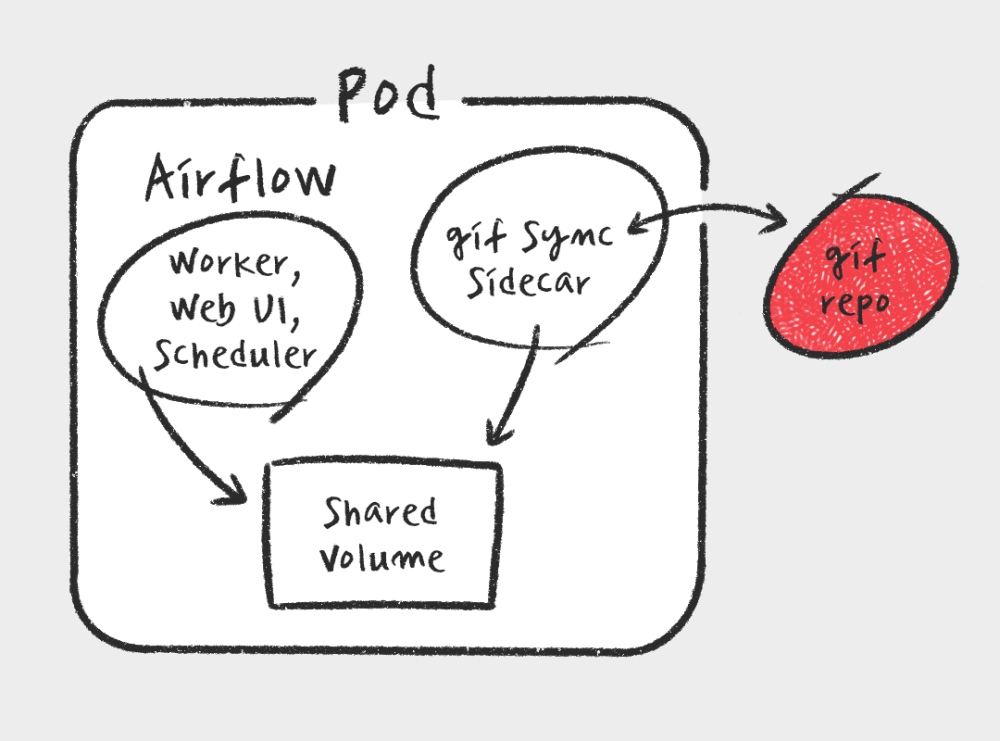
Kubernetes Executor에서는 매 Task마다 새로운 pod를 생성하여 Task를 실행하기 때문에 모든 Worker pod는 DAG 코드를 가지고 있어야 합니다. 크게 3가지 방법으로 DAG 코드를 Worker로 전달합니다.
- git sync sidecar : pod에 git sync sidecar를 같이 실행하여 최신의 DAG 코드를 깃에서 가져오게 하는 방법
- shared volume : Kubernetes PersistentVolume에 DAG코드를 저장해두고 scheduler/web server/ 워커에 마운트 하는 방법
- Airflow 이미지에 복사하는 방법
이미지에 복사하는 방법은 DAG 코드에 변경이 있을때마다 scheduler/web server의 배포가 필요하기 때문에 코드 추가와 변경이 잦은 버킷플레이스 데이터팀과는 맞지 않다고 판단했습니다. shared volume을 사용하는 것도 좋은 방법이라고 생각했지만, PersistentVolume까지 DAG를 전달하는 CI/CD 파이프라인을 또 만들기 번거롭기에 git sync sidecar를 사용하기로 마음 먹었습니다. DAG 레포에 코드가 커밋되면 사이드카에서 자동으로 Airflow 모든 pod에 최신 코드로 업데이트를 해줘서 중간 과정에 큰 고민없이 DAG 코드를 작성하고 Airflow에서 실행할수 있습니다.
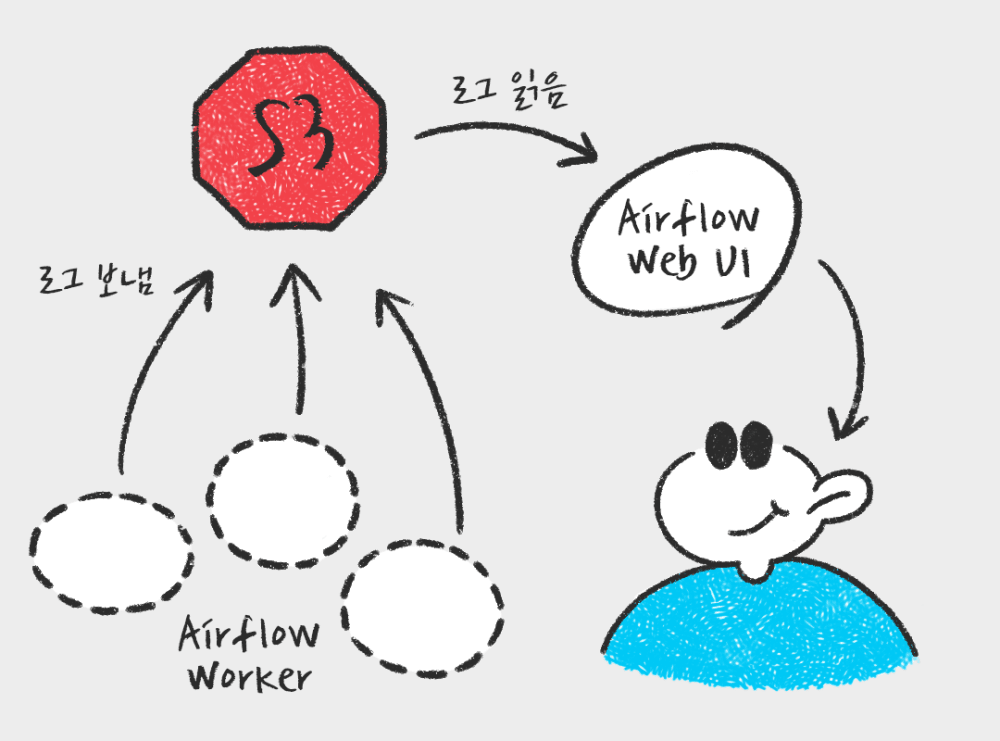
또, Kubernetes Executor가 Task를 실행하는 Worker pod는 실행이 종료되면 사라지는 휘발성을 가지고 있습니다. 따라서 각 Task의 로그 파일도 사라지게 됩니다. 많은 사람들이 추천하는 방식인 remote bucket(S3)을 사용하여 로그를 남기도록 설정, 문제를 해결하였습니다.
DAG 작성
Airflow를 Kubernetes 에 성공적으로 배포하고 기존에 사용하던 Jenkins에서 하나하나씩 task를 옮겨오기 시작하였습니다. 기존에 젠킨스에 사용하던 코드 레포를 그대로 git sync로 airflow로 가져와서 하나씩 DAG를 작성하기 시작했습니다. 그 과정에서 고려한 몇 가지를 적어두었습니다.
Airflow의 시간
start_date 와 schedule_interval
Airflow는 기본적으로 UTC 시간 만을 사용합니다. 가장 최근 Airflow 버젼에서는 시간대를 변경하는 기능이 추가 된 것 같지만, 버킷플레이스에서 도입하던 시기에는 UTC 시간만을 지원해서 개발의 불편함이 있었습니다. Airflow에서 중요한 시간인 DAG 시작 날짜 start_date 와 스케줄링 주기 schedule_interval 를 KST로 표현하고 싶었습니다.
Airflow 자체의 코드를 확인해보면 start_date는 python datetime object, schedule_interval은 cron으로 표현된것을 timedelta object로 변경하여 사용하는것을 확인할 수 있습니다. start_date를 기준으로 schedule_interval을 더해가면서 DAG를 scheduling 하는 원리입니다. 따라서 start_date만 잘 표현해주면 한국시간 기준으로 schedule_interval을 작성할수 있습니다.
DAG마다 한국 시간 Timezone을 명시 해줌으로 시간에 대한 큰 고민없이 DAG 코드를 작성할수 있었습니다.
import pendulum
from airflow import DAG
from datetime import datetime, timedelta
# 한국 시간 timezone 설정
kst = pendulum.timezone("Asia/Seoul")
# 한국 시간 2021년 1월 1일 시작, 오전 8시마다 실행되는 DAG 설정
dag = DAG(
dag_id="test_dag",
default_args=default_args,
start_date=datetime(2021, 1, 1, tzinfo=kst),
schedule_interval="0 8 * * *",
)
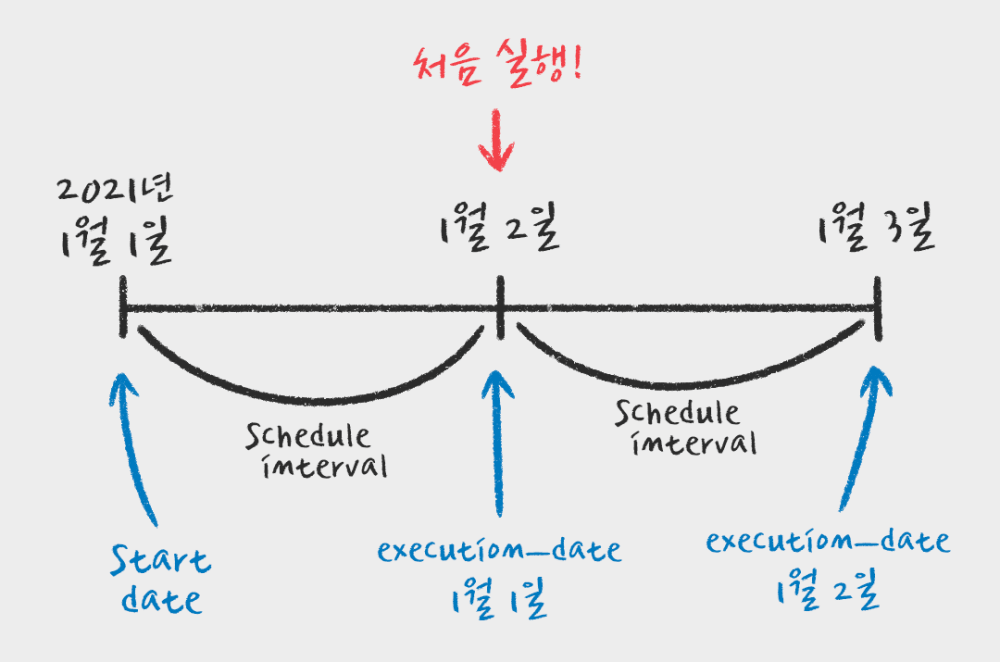
이렇게 작성된 코드만 보면 2021년 1월 1일날 오전 8시에 처음 실행된다고 생각할수 있습니다. 하지만 실제로는 1월 2일날 오전 8시에 처음 실행됩니다.
Airflow의 execution_date
Airflow에서 start_date는 실행 시작 날짜가 아니라 스케줄이 시작 되는 날짜입니다. 위와 같은 경우, 1월 1일부터 하루에 한번씩 8시에 스케줄이 등록되고, 하루 뒤인 1월2일부터 execution_date가 1월 1일인 DAG가 실행된다는 것입니다. 이 execution_date는 나중에 해당 DAG를 다시 실행해도 그대로 1월 1일로 유지되는 이 DAG고유 실행 Id 같은 값입니다.
cron 과 같은 scheduler처럼 생각하면 이 execution_date는 잘 이해가 가지 않습니다. 하지만 ETL관점에서 증분을 생각하면 이해하기 쉽습니다. execution_date가 1월 1일인 task의 경우 1월1일의 data를 가지고 ETL을 한다고 예상할수 있습니다. 1월1일 데이터는 1월2일이 되어야 모두 존재하기 때문에 Airflow는 이런 방식의 시간을 설정하고 있습니다.
이 execution_date 를 또 DAG에서 파라미터로 한국 시간으로 사용하기 위해 바로 사용하지 못하고 Jinja template를 활용하여 start_date 와 같이 한국 시간으로 변경하여 사용해주고 있습니다.
DAG가 실제 실행되는 시간을 기준으로 어제와 오늘의 한국 시간을 변수로 다음처럼 사용합니다.
YESTERDAY = '{{ execution_date.in_timezone("Asia/Seoul").strftime("%Y-%m-%d") }}'
TODAY = '{{ next_execution_date.in_timezone("Asia/Seoul").strftime("%Y-%m-%d") }}'
Backfill and Catchup
과거에 start_date를 설정하면 Airflow는 과거의 Task를 차례대로 실행하는 Backfill을 실행합니다. 간혹 "과거 언제부터 데이터를 쭈욱 빌드해주세요" 라는 요청을 받으면 과거 start_date를 잘 설정하기만 하면 빌드는 자동으로 과거부터 실행되어 편리하게 데이터를 빌드할 수 있습니다. 하지만 이런 동작을 원하지 않는 경우도 많이 있습니다. 그럴때는 DAG 를 선언할때 Catchup 설정을 False로 해주면 Backfill을 실행하지 않습니다.
dag = DAG(
dag_id="test_dag",
default_args=default_args,
start_date=datetime(2021, 1, 1, tzinfo=kst),
schedule_interval="0 8 * * *",
catchUp=False,
)
Airflow Operator 잘 사용하기
버킷플레이스 데이터팀에서 가장 많이 사용하는 Operator는 BashOperator 와 PythonOperator 입니다. 가장 기본적이면서도 다양한 Task를 실행 할 수 있어서 널리 사용하고 있습니다.
BashOperator는 말 그대로 Bash command를 실행할 수 있게 해줍니다. BashOperator를 사용할때 염두해야할 것은 Airflow는 Temp directory를 생성하여 해당 위치에서 BashOperator를 실행한다는 점입니다. 따라서 DAG레포와 같이 있는 Script를 실행하기 위해서는 Script의 위치를 정확하게 지정해줘야합니다.
run_my_bash_script = BashOperator(
task_id="run_my_bash_script",
bash_command="""
sh $AIRFLOW_HOME/dags/scripts/my_bash_script
""",
dag=dag,
)
PythonOperator는 Python 함수를 실행시켜줍니다. PythonOperator를 통해 실행하는 함수에 변수를 넘겨주기 위해서는 Operator를 통해서 op_args나 op_kwargs를 이용해야합니다.
run_my_python_function = PythonOperator(
task_id="run_my_python_function",
python_callable=my_python_function,
op_args=[1, 2, 3],
op_kwargs={"number": 10},
dag=dag,
)
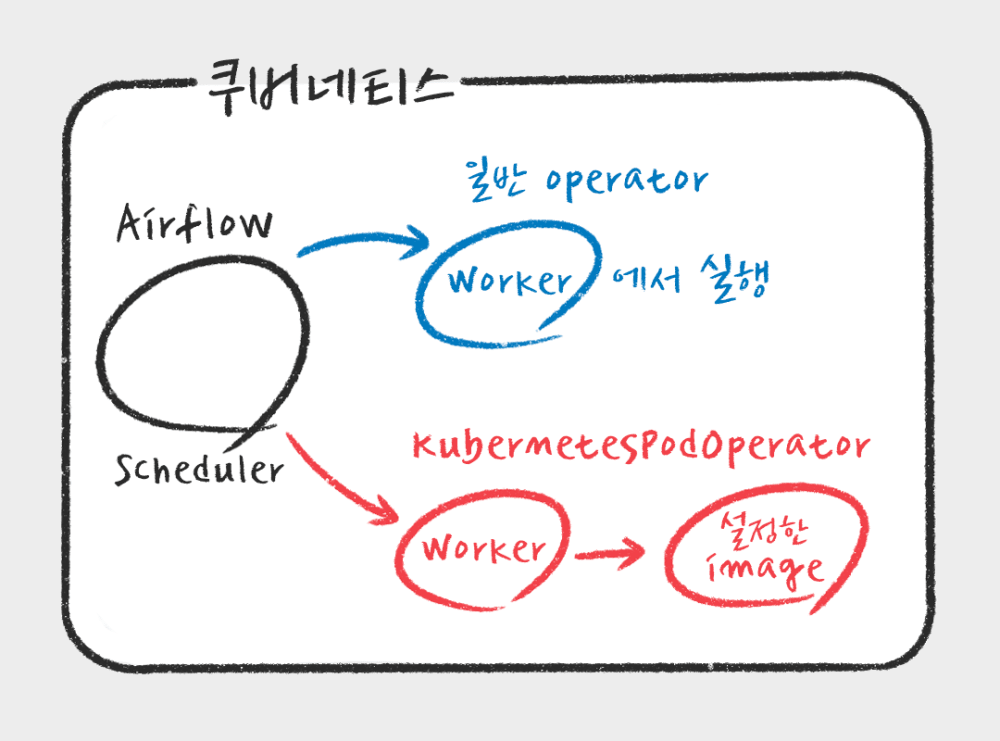
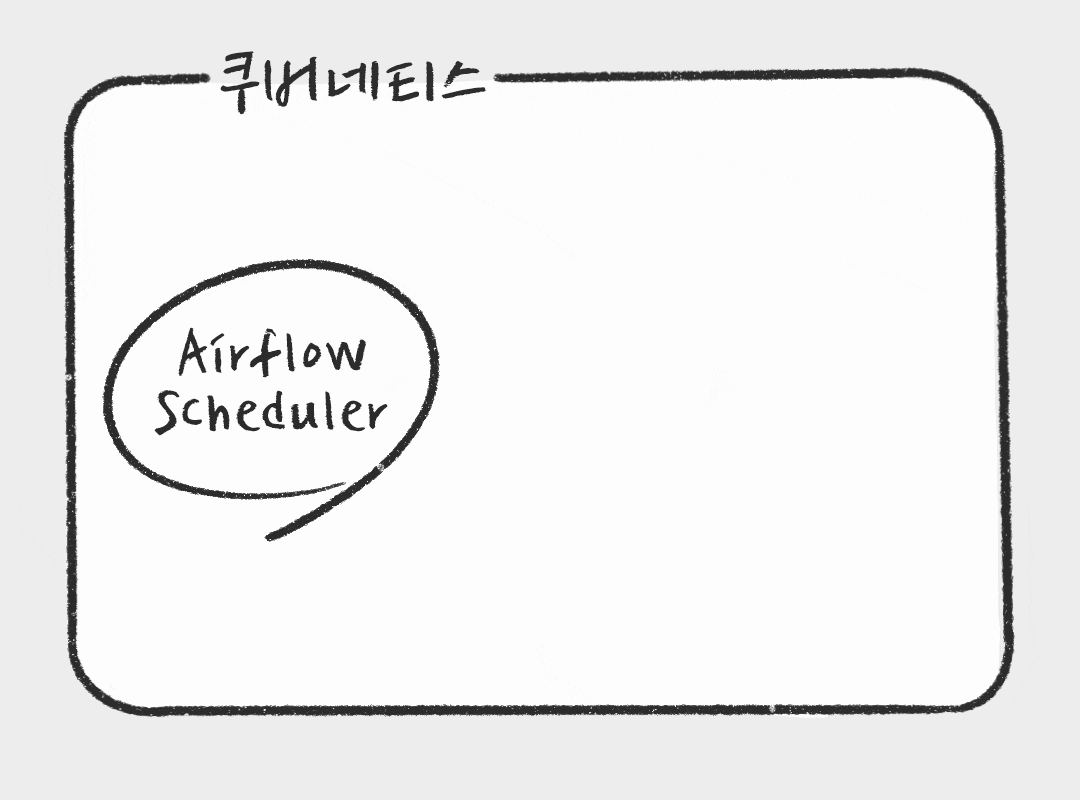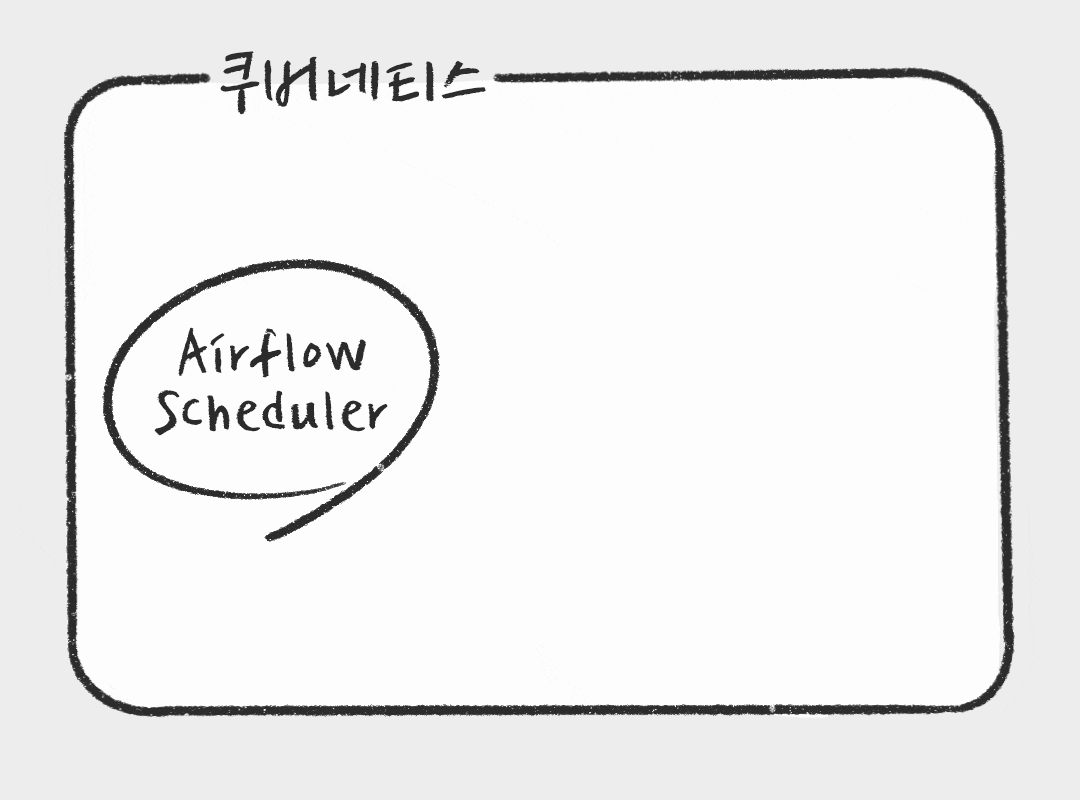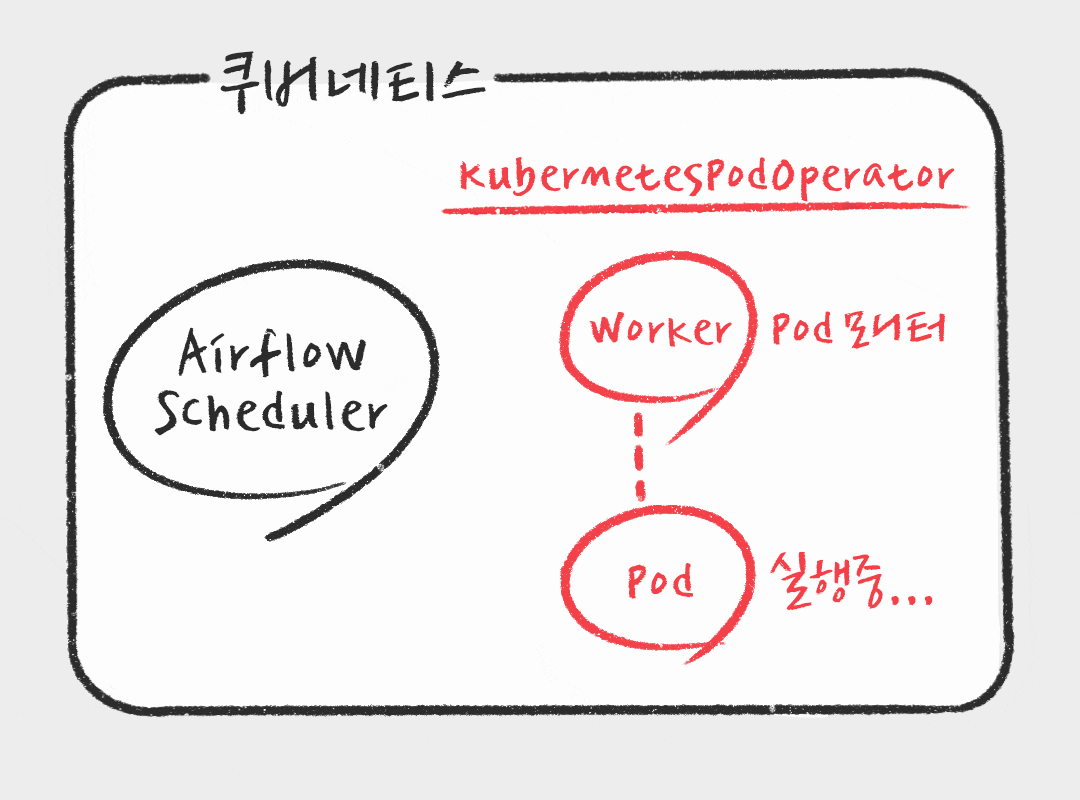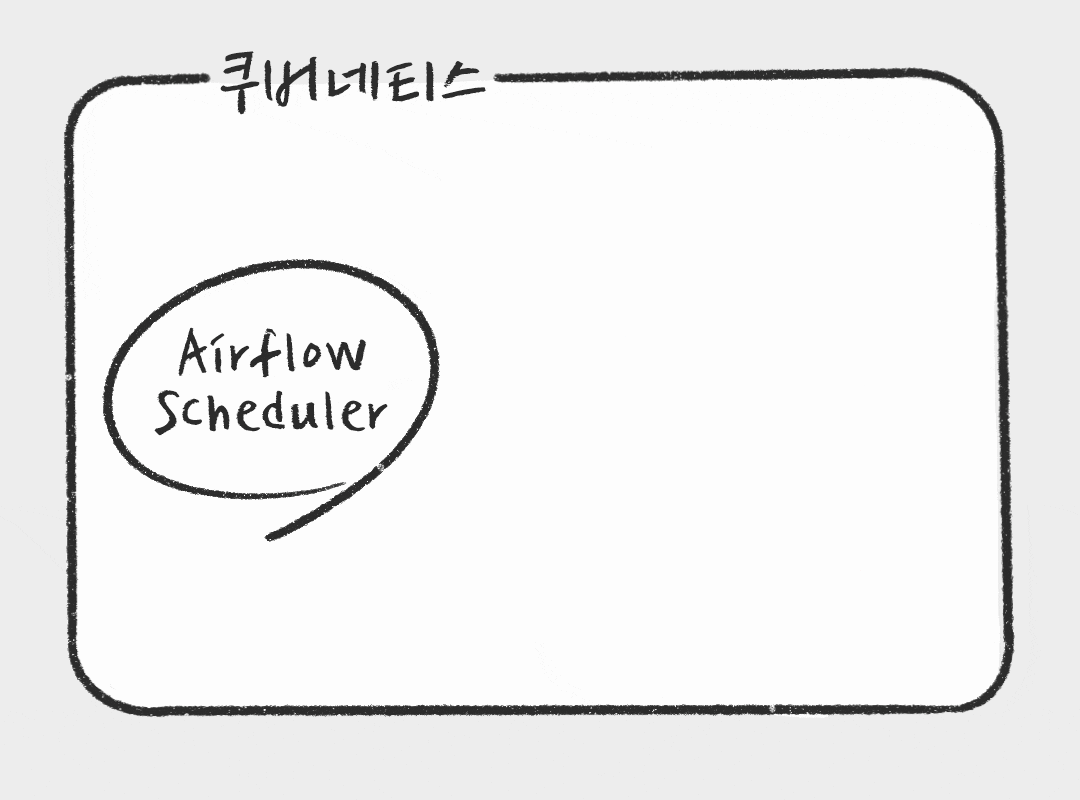
버킷플레이스 데이터팀에서는 더 복잡하고 다양한 Task를 위해서는 KubernetesPodOperator를 사용하고 있습니다. KubernetesPodOperator는 쿠버네티스 환경에서 Airflow Worker가 지정한 이미지로 새로운 pod을 생성하여 Task를 실행할수 있게 해줍니다. Kubernetes API를 모두 활용하여 pod 실행을 조절 할 수 있기 때문에 다른 namespace에서 pod 실행할수도 있고, spark, hive 등 환경을 빠르고 쉽게 컨테이너를 이용하여 실행하여 원하는 Task를 실행할 수 있습니다.
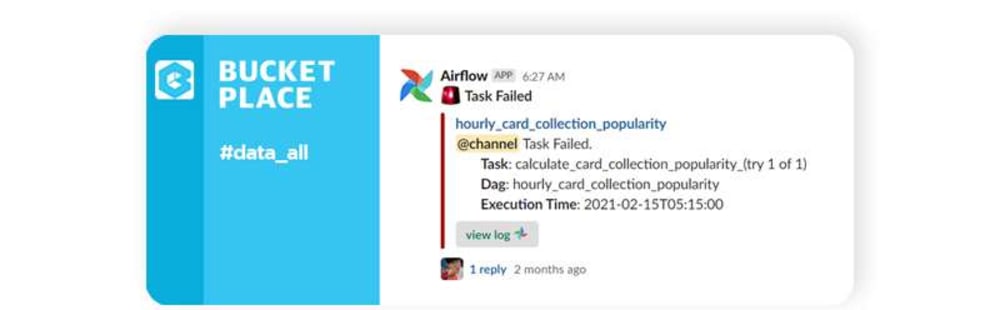
또한 slackOperator를 상속하여 오늘의집에 맞게 잘 수정한후 on_failure_callback 으로 사용하고 있습니다. https://gist.github.com/ddelange/6e33f8f0df3a97d4a371d055aa2d58ac를 참고하여 Airflow에서 Task가 실패하면 빠르게 slack으로 받아볼수 있게 slackOperator를 잘 구성해 더 안정적으로 데이터파이프라인 모니터링을 할 수 있습니다.
DRY(Don't Repeat Yourself) 한 DAG 작성하기
DAG를 작성하다 보니 Task에 변수 하나만 빼고 동일한 경우가 있습니다. 이런 경우 똑같은 Task를 여러번 작성하는것은 DRY하지 못합니다. 이런 경우 간단하게 for 루프를 돌면서 Task를 생성하는 방법으로 코드는 단순하게 만들 수 있었습니다.
alphabets = ["a", "b", "c", "d", "e"]
tasks = {}
for alphabet in alphabets:
task = PythonOperator(
task_id=f"print_{alphabet}",
python_callable=print_alphabet,
op_kwargs={"alphabet": alphabet},
dag=dag,
)
tasks[alphabet] = task
tasks["a"] >> tasks["b"] >> tasks["c"] >> tasks["d"] >> tasks["e"]
현재 그리고 앞으로..
Airflow로 옮겨온 지 어느 정도 시간이 지났습니다. 쿠버네티스 환경을 구축하면서 많은 시행착오가 있었지만, 지금은 Airflow를 성공적으로 사용하고 있습니다. 전에 비해 모니터링, 확장성은 물론, 개발도 편리해져 매우 만족스럽게 사용하고 있습니다. 마지막으로 지금 버킷플레이스에서 Airflow 관련 테스트하고 있는것들을 공유하면서 마무리 하겠습니다.
Airflow를 사용하면서 불편한점 한 가지는 KubernetesExecutor를 사용하여 실행하고 있는 Task의 로그를 볼수 없고, worker pod의 로그만 볼수 있다는 점입니다. https://github.com/apache/airflow/blob/1.10.15/airflow/utils/log/file_task_handler.py#L111 코드를 보면 pod의 로그를 읽는 부분을 확인할수 있는데, Task가 쓰는 로그 파일을 읽지 않아서 이런 불편함이 있음을 확인하였습니다. 이 부분이 Airflow 2.0 버전에서도 해결되자 않아 아래와 같은 방식으로 monkey patch하여 해결해보려고 테스트해보고 있습니다.
res = kubernetes_stream(
kube_client.connect_get_namespaced_pod_exec,
ti.hostname,
conf.get('kubernetes', 'namespace'),
command=['cat', location],
stderr=True,
stdin=False,
stdout=True,
tty=False,
_preload_content=False,
)
또한 Airflow가 2.0 버전을 발표하면서 많은 내용이 변경되었습니다. Scheduler HA 지원과 web server UI 변경, DAG 작성 방식도 변경되었고, 그 이외에도 수많은 변경사항이 있었습니다. 이에 오늘의집에서도 Airflow 2.0 버전 업그레이드를 위한 테스트를 하나씩 해보고 있습니다.
